1 科学目标与功能
建设材料计算与数据处理子平台,是一个面向材料物性需求,利用第一性原理材料计算,在材料数据驱动指引下进行材料研发的用户服务系统,集材料计算、方法开发、算法发展、数据存储、数据挖掘、机器学习、材料搜索、智能推荐等多种功能于一体,致力于探寻材料的组分-结构-性能之间的关系,实现材料的理性设计,加速新材料的发现和研发,满足材料基因组研究的要求。结合北京光源和综合极端条件设施等大科学装置,建设虚拟光源和虚拟极端条件装置,为大科学装置提供材料物性研究的理论支持和计算模拟,实现超快、超强、超细等实验达不到的极限分辨。
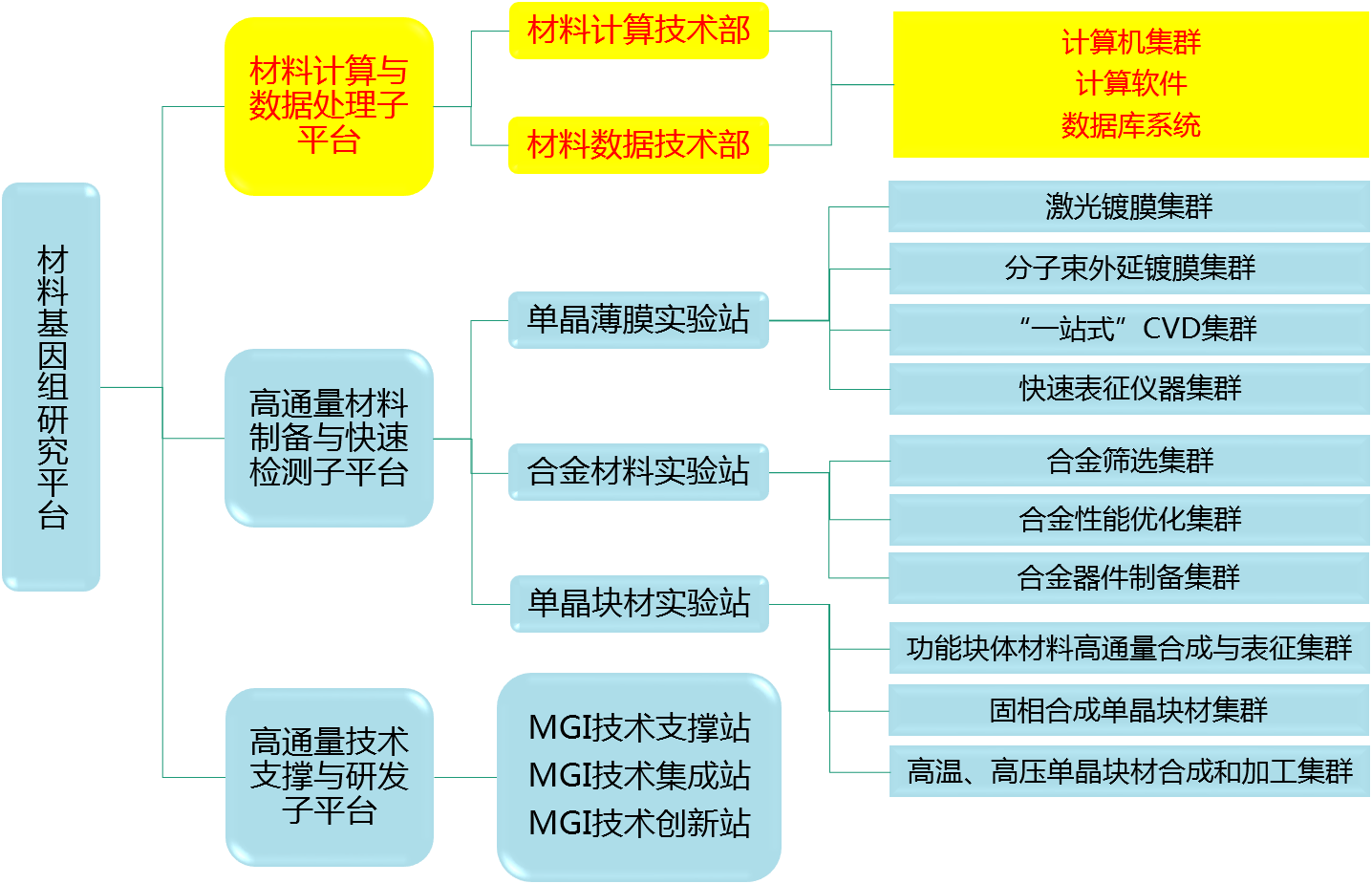
2 子平台构成和设计方案
计算在当代材料研究中尤其是材料设计中发挥着关键作用。基于量子力学等物理学基本原理,原则上只要知道原子组份,材料的所有性质(化学、机械、电学、磁学、光学、热学,等等),就都可以依据这些物理学原理通过大规模计算预测出来。这种计算无需任何人为的经验参数,很接近于反映宇宙本质的原理,所以被称为第一性原理计算。随着计算机硬件、软件以及算法等技术的进步,当前第一性原理计算已经可以在适当的时间内给出相当精度的材料性质模拟和预测,并成为当前物理、化学、材料等领域的重要研究方向和研究手段。材料基因组研究将充分利用高通量的理论计算模拟,结合可靠实验,创建一个能够准确识别和预测成千上万种化合物组分、结构和性能的数据库,为材料学的研究和分析增加一个“信息学”的维度,应用强大的统计学方法,在物理意义上预测出更多复杂的多维信息,并找出潜在隐藏的关系模式。就像基因组学对生物学领域的影响一样,这种信息学方法的应用对材料设计和发现将具有非常重要的影响。
材料基因组平台中,材料计算和数据子平台要建设成一个集材料计算,方法开发,算法发展,数据存储,数据挖掘,机器学习,材料搜索,智能推荐等多种基于计算和数据的材料研发功能的用户服务系统,从而能够实现材料理性设计,加速新材料的发现和研发,满足材料基因组研究的要求。它将具备以下主要功能:
1) 基于量子力学原理的大规模材料计算,支持高通量并发任务,支持自动智能计算流程。
2) 材料计算方法、算法和软件的开发、共享和应用。
3) 材料理论计算和实验测试数据的采集、存储、挖掘、分析,以及多种异构数据的可视化。
4) 材料模拟器,研究和预测材料在高温、高压、强场、超快和辐照等极端条件下的行为和性质。
5) 虚拟光源,模拟光与物质的各种相互作用,材料的响应及相关动力学过程。
6) 面向特定功能需求,应用数据挖掘,机器学习等手段,基于材料数据库进行搜索、智能推荐、多层次设计与计算等。
7) 材料计算与数据子平台将提供强大的材料计算和材料数据处理能力,发展从单个原子、分子,到表面、薄膜,到大块体材的跨尺度材料模拟方法,开发基于量子力学基本原理的量子蒙特卡洛及量子动力学,多体势函数分子动力学,粗粒化的相场模拟和相图计算等跨层次算法,能够从阿秒到秒乃至若干年的时间尺度上跟踪模拟材料的性能变化。存储各类材料的晶格、结构、电子结构、光学性质、相图等多方面的性质数据,基于这些材料数据提供材料搜索、智能推荐等服务,可以完整地预测材料结构和性能,为实现材料基因组计划起到引领作用。
根据以上总体设计思路,材料计算和数据处理子平台可以分为三个子系统:高通量材料计算,材料基因数据库,机房基础设施。在此基础之上建成三个功能模块:虚拟极端条件、虚拟光源、材料智能推荐。上述系统的建设相对独立又相辅相成。以下就各个系统的设计方案分别阐述。
3 系统主要参数
从材料计算和数据处理平台的业务功能,业务流程,业务量,信息量等角度对主要指标,关键设备参数等给出核算依据和核算方案。1、业务功能:材料计算与数据处理子平台的主要业务功能是满足高通量材料制备和快速检测平台的材料物性计算需求,在此基础上进行更广泛的材料相图计算,达到指引材料创新和性能优化的目的。同时为极端条件设施大科学装置和北京光源提供理论计算模拟和支撑。
2、业务流程:高通量制备和快速检测子平台、极端条件设施大科学装置和北京光源等每天或每周提出材料计算需求,所有样品的检测数据存入数据库系统。材料计算与数据处理子平台对这些材料和数据进行计算、模拟、校验、分类、存储和可视化处理等。在此基础上进行结构、组份、压力、辐照等多维相图计算,探索新材料,提出优化方案,反馈给实验子平台。
3、业务量:按照设计目标,预计平均每天有300多个样品。按照当前第一性原理材料计算软件在规划中的计算设备上的运算速度(譬如,通常平面波赝势方法利用单CPU核计算20个原子大小的原胞大约需要4小时左右),需要的计算时间大约是1500核小时。与此同时,高通量材料计算需要根据实验样品的测量数据,在材料的结构、组份、掺杂、压力等多个维度进行拓展计算,通常拓展相图的计算量是已知实验材料的100~1000倍,这样需要的计算资源的需求量是15万核时~150万核时每天,因此初期的建设规划是规模是8000CPU核(每天可提供19万核时计算资源)。按照每个结点28个CPU核,需要300个节点。这样的计算机系统建成后的理论双精度峰值性能是322TFlops,考虑到实际软件计算效率,把整体双精度峰值性能设为200TFlops比较合理。
4、信息量:实验检测数据大约每个样品约100条左右,包括结构、组份、缺陷、掺杂、载流子类别和浓度,力学性质、光学性质、磁学性质等,大约存储需求约0.1M左右。因此,每天的实验数据存储需求大概是300*100*0.1M=3G,5年的需求大约是365*5*3G=5475G。每个第一性原理计算任务的存储需求大概是20M,那么每天计算产生的数据量是300*100*20M=600G。5年的数据存储需求1095TB。考虑到数据冗余需求,存储系统的容量大约是2000TB。
5、MGI的扩展:由于材料研究的持续进展,预计会有大量的新材料体系,新功能要素被发现和发展,对于高通量材料计算和数据处理子平台会有持续的计算、存储和处理需求。我们在设计机房和能源供应时,已经充分考虑了机房的面积,设备更新的操作空间,制冷设备的功率,输入电源的功率需求等,具体内容见机房的具体设计。
材料计算与数据处理子平台的主要验收指标为:
材料计算系统CPU双精度浮点计算能力:>200万亿次。CPU核数:>8000个。
材料数据系统的存储能力:>2.0PB。
支持高通量材料计算并发任务数:>1000。
材料性质信息:>10000条;
支持并发用户数:>10000个;
部署特色的高通量材料计算专用软件:支持LDA+G强关联材料第一原理软件BSTATE,大规模材料模拟软件OpenMX,和激发态第一原理计算软件TDAP等。
预测有特殊性质和应用前景的新材料:10种以上。
其中高通量计算机需要满足:
1. 高性能计算系统整体双精度峰值性能为200TFlops,共>8000计算核心,另外配置少量GPU/KNL以及胖节点满足不同软件对计算资源的多样化需求;
2. 采用Parastor300并行存储系统作为集群的共享存储,裸容量>1920TB;
3. 采用最新主流100Gb/s EDR InfiniBand作为计算数据网路;
4. 配置登陆节点、管理节点等功能节点6台;
5. 方案提供完备的集群系统软件,包括:节点Linux操作系统;曙光Gridview集群操作系统,提供系统监控、管理、告警、统计、作业调度等功能和组件;GNU、Intel等编译环境,BLAS、LAPACK、FFTW、Intel MKL等常用数学函数库,OpenMP及MPI并行开发环境;IT系统功耗(不含空调制冷系统)约为255千瓦;

版权所有 © 中国科学院物理研究所 Copyright © Institute of Physics Chinese Academy of Sciences